克雷格·文特(Craig Venter,下图)是人类基因组计划(HGP)的另一个知名领袖,他领导的私营企业赛莱拉基因组学公司不仅加快了整个人类基因组计划的进程,而且创建了有效推进生命大科学项目的新模式。他在这篇文章中称,基因组数据很快将成为一种商品,下一个挑战――把人类的遗传变异与生理学和疾病联系起来――将和十年前基因组科学家面临的挑战一样伟大。

2006年6月,当时任总统克林顿在白宫宣布人类基因组最初的两张草图诞生以来,时光已流逝了近十年。十年来,DNA测序技术取得了比任何人可能预料的更具戏剧性的进展:通过世界范围的努力、花费数十亿美元,人类基因组计划达到了一些人认为不可能实现的目标。为了争先发表第一张人类基因组草图,赛莱拉基因组学公司当时与弗朗西斯·柯林斯(Francis Collins)领导的公立研究机构展开了竞赛,这在某种程度上也是一场创新的竞赛。今天,用一天时间就可测序一个人的基因组,且仅需花费几千美元。
然而,在测序能力对医学和健康产生后续影响之前,还有一段路要走。随着测序成本继续下降,数据质量需要进一步的提高。如果没有个体可观测性状的表型信息和将两者加以联系的计算工具,基因组的数据产生将几乎毫无价值。研究人员今天面对的挑战,至少像我和我的同事十年前遭遇时一样令人却步。
事后的认识
出于多种原因,人类基因组计划从一开始就备受争议,特别是有可能“侵占”其他生物研究项目计划的资金。1989年,预计未来几年测序成本将降至1美元1对碱基,相关机构决定请求国会拨款30亿美元,对30亿对碱基组成的人类单倍体基因组进行测序,而不是对60亿对碱基(二倍体基因组)进行测序。当时认为测序费用60亿美元太昂贵了。
1994年,由于进展缓慢和低效劳作带来的挫败感,我和我的团队开发出了“全基因组鸟枪测序法”,在3个月内,我们对整个细菌基因组进行了测序。5年后,赛莱拉公司将这一方法运用到果蝇和人类基因组上。从2001年起,这一曾极具争议的方法一直被用于对几乎每个基因组的测序。
在赛莱拉公司进行的工作是在一台大型设备上完成的,由300台自动化DNA测序仪和1台功能强大的计算机组成;而公立机构使用了大约600台DNA测序仪,分布在世界各地的几个实验室中。总之,第一次得到的两张人类基因组草图使我们对人类自身有了深刻的了解。其中,最重大的发现是人类基因的数量很少――只有约26000个――而早期的估计是30万个左右。
随着人类基因组草图在2001年公诸于世,许多分析家预测DNA测序技术的市场已走到尽头。正如我们现在知道的故事不仅没有结束,而且以一个截然不同的方式展开了。测序的重心转向了动物学,非人类的测序基因组总数量迄今已超过3800种(见表1)。与此同时,来自世界各地实验室的数据在充实到草图后,最终导致2004年推出了人类基因组草图的改良版。基于我的团队完成了对我本人基因组的测序,2007年公布了第一个来自个人的二倍体人类基因组。
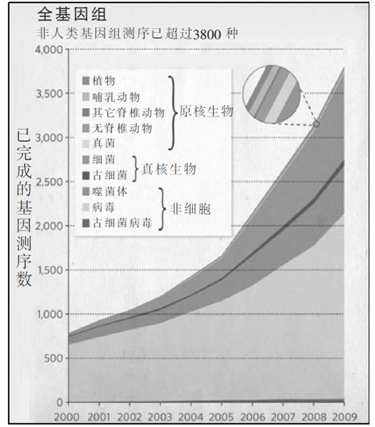
表一数据来源:欧洲核苷酸档案库和ENSEMBL基因组
更大的差异
第一个二倍体人类基因组展示了人类多样性的新画面。测序结果显示,当DNA序列中插入和删除核苷酸、单核苷酸多态性(SNPs)等情况时,我的两个亲缘基因组彼此存在0.5%的差异,与2001年得出的估计值0.1%相比有显著增加。后来发现,不同的个人基因组的差异在1% —— 3%之间。
为什么第一次得到的人类基因组草图的数据没有显示出如此显著的差异?原因在于当时公立研究机构进行的是单倍体基因组测序,没法直接检测多态性、插入和删除。与此相反,赛莱拉公司进行的基因组测序存有太多的遗传变异。由于DNA样品来自不同的种族以及早期测序软件的局限性(单一共用序列),忽略了相当数量的来自每个基因组的插入和删除。如果我们当时只用一个人的DNA样品,就会对这一差异有一个更加全面的了解。
今年早些时候,加利福尼亚州两家公司开始出售新的测序仪,它们每天能分别处理250亿和1000亿对碱基(另有公司宣布正在研制每天能处理3000亿对碱基的新仪器)。据悉,这些仪器能以低于6000美元、在一天内完成一个人的基因组的测序;而1987年,我在美国国立卫生研究院(NIH)实验室的第一台测序仪每天只能处理4800对碱基。23年后,测序速度提高了约8个数量级。
下一个挑战
提高数据质量是至关重要的,如果一个人基因组不能被独立组装,那么这些序列数据就不能被分到两套亲缘基因组或单体型中。这个过程――单体型定相――将成为基因组医学中最有用的工具之一。把我们从亲缘基因组收集到的整套信息建立起来,这对理解遗传性、基因功能、调控序列和疾病易感性之间的联系具有决定性作用。幸运的是,现在已经有了一些令人兴奋的进展,能帮助我们从单条DNA链中产生序列信息。这种方法有希望在数千对碱基的范围内进行序列读取,并将导致产生更高质量的基因组序列数据。
按照当前技术进步的速度,形成价廉质高的序列数据库将不再是一个难题。若要改变医学现状,揭示人类遗传变异与生理学、疾病等生物学后果之间的联系,必须在实验过程中动用数万人的完整基因组以及综合性的数字化表型数据。例如,若要了解某人是否患有糖尿病,就必须了解诸如其发病年龄、与疾病有关的临床表现等,包括神经损伤程度、血管状况、用药剂量和家族史等。
然而,即使我们掌握了所有这些信息,仍然还无法加以利用。因为我们目前还没有可将数千个基因型和表现型进行比较的计算基础设施。这种需求可能是提议建造“亿亿级”(1秒内完成亿亿次运算)超级计算机的最好理由,其运行速度比现今最快的计算机快1000倍。因此,科学家需要在全球层面上展开工作,以确定表现型数据的标准。
从现在开始,基因组学在十年后将会有怎样的进展呢?随着全球性测序能力的增强和数据质量的提高,我们将超越每人一个基因组的现行目标而扩展到包括以精子、卵细胞、囊胚、干细胞、前癌细胞和癌细胞为目标,对每个人的多重基因组进行测序。这样,我们就能选取健康细胞进行复制和组织移植,更好地理解衰老和肿瘤的发展趋势。
对医学进步同样重要的,还包括对栖息在我们体内数百万微生物的基因组进行测序。从这些方面而言,基因组革命才刚刚开始。
资料来源 Nature
责任编辑 则 鸣