蛋白组学的发展不仅需要包括数据库整合在内的新技术的发展和新实验战略的建立,而且还需要学科转移(扩散、辐射)和跨学科合作的精神——
如果为你设计房屋的建筑师给你一份由一大堆专门术语和长长的材料清单组成的蓝图,你可能会对你能不能以及什么时候能见到你的新房屋感到疑惑。对于最近(2001年2月)“完成”的人类基因组序列,宣称将给生物学和医学带来革命的“遗传学蓝图”,也使有些人持有相似的保留意见。在对蕴藏其中的基因进行诠释之前,人们是不可能阐明107个核苷酸是如何决定一个酵母细胞的,更不用说3×109个核苷酸是如何决定每个具体的人的存在了。这关键的一步包括弄懂这些基因编码的蛋白质和它们对生命的存在起到什么样的作用。但是理解所有这些蛋白质是如何相互合作以完成各种细胞机制,才是即将到来的真正雄心勃勃的事业。
在全套基因组序列的美妙图景中,有许多东西是基因组学(genomics)不能解决的问题,因而未来是属于蛋白组学(proteomics,也译作蛋白质组学)的:这就是对整套蛋白质的分析。蛋白组学不仅包括对各种蛋白质的识别和定量化,还包括确定它们的(细胞内外的)定位、修饰、相互反应、活性,和最终确定它们的功能。蛋白组学最初的主要技术仅仅是用于蛋白质分离和鉴定的二维凝胶电泳技术,目前蛋白组学却是指对大量蛋白质的集合的研究。这个领域的急剧发展受到了多种力量的驱动:基因组学及其与越来越多新蛋白质的关系;强有力的蛋白质分析技术,例如新建立的质谱仪方法(masss pectrometry approaches)、全局双杂交技术(global two-hybrid techniques)和DNA阵列(DNA arrays)技术在蛋白质分析中的派生技术;以及各种用于处理、分析和解释庞大数据的新颖的计算工具和方法。
人们的思考从基因组学到蛋白组学的转移,是由于充分觉察到研究任务的难度:蛋白质比核酸更加复杂。与貌似具有很大挑战性的DNA不同的是,蛋白质要进行磷酸化、糖基化、乙酰化、遍在化、硫酸化、与糖基化磷脂酰肌醇锚泊蛋白相连接,和许多其他方式的转录后修饰。一个基因可以编码多个不同的蛋白质——这一过程的完成要通过mRNA转录本的选择性剪切、翻译起始位点或终止位点的改变,或者使mRNA翻译中的三联密码发生改变的读框移动等。所有这些可能发生的事件导致蛋白组比之基因组要复杂、庞大许多数量级。(所以,人类基因组的基因数量仅仅是酵母基因数量的6倍可能对蛋白组学家们是一件幸运之事!)而且,蛋白质还会对它所处环境发生的改变进行应答,这些应答包括:改变它们在细胞中的定位、被裂解成片断、调节它们的稳定性、以及改变它们所结合的物质(包括其他蛋白质、核酸、脂质、小分子、或者其他配体)。蛋白质的水平经常并不反映mRNA的水平,即使是存在一个开放读框也不能保证存在一种蛋白质。最后,一种蛋白质可以与不止一种(生化)过程有关,相反,不同的蛋白质可以完成相同的功能。
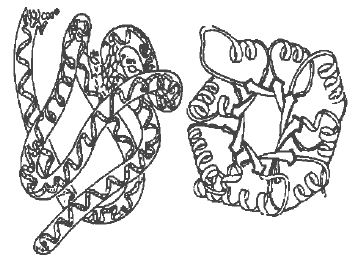
肌红蛋白(左)与丙糖磷酸异构酶结构图
我们现在何处
值得一提的是,在前蛋白组学时代(pre-proteomicera),数以千计的蛋白质已得到了精细的研究,这些蛋白质存在于代谢和信号传导途径中;复制、转录和翻译机制中;分泌和细胞骨架网络中;以及一大堆其他细胞复合体中。这些功能的认定是由于人们为认识特定的细胞机制作出了重大的努力,有三个主要因素推动了近20年来的进步。首先,遗传学家、细胞生物学家、生物化学家和结构生物学家从各自不同的学科汇聚在一起,来研究各种共同的问题。其次,基本细胞学机制的不同寻常的保守性使得从一种生物体的研究中积累起来的知识可以立刻应用在所有其他生物体中。第三,技术的发展——包括分子生物学所用的现行标准手段如DNA测序、重组DNA和聚合酶链反应(PCR)——促进了新的实验战略的发展。
随着蛋白组学的出现,许多其他的蛋白质正在加入进来与那些早已在某些(细胞)机制中有所涉及的蛋白质相汇合。但是,这些额外的信息并不是来自持续至今的小规模的生物学活性分析,而是来自一些更大、更系统的研究。与其前体学科(或称上游学科)基因组学一样,蛋白组学因此而代表了一种新出现的科学研究的新方法,它并不依赖于对细胞行为的特定模式的检测。显然,这种科学并不替代、而是将日益与传统的生物学研究方法一起联合使用。
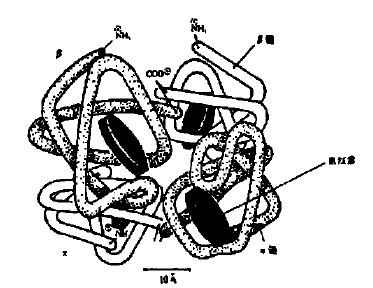
面红蛋白亚基结构模式图
一个基本的原则是:蛋白质总是与细胞中同该蛋白质一起完成一定生物学功能的其他蛋白质一起出现的;因此,鉴定细胞溶解后复合体中完整无缺的新蛋白质,就经常为功能的发现提供了线索。一个巨大的推动来自最近在质谱仪方面的进步,可以快速识别在二维凝胶中或通过色谱仪进行分离的蛋白质。质谱仪可以测出大量的肽(一般来自于胰蛋白酶降解),然后可以与从基因组数据库中进行电子降解(in silico digestions)得到的大量预测肽进行比较。在串联质谱仪中,第一台质谱仪中产生的肽离子被降解为片断、在第二台质谱仪中被识别,从而产生出更加有价值的肽序列产品。一条单一的肽序列通常能够识别出一种蛋白质。自动化程度的提高、敏感性的增加、更高的通量,以及改善了的生物化学分馏和急剧扩大的数据库的可以利用,已经扩展了质谱仪技术的应用,可以完成更大的工作任务。即使不用凝胶分离,直接的蛋白质复合体的分析也可以识别异源的蛋白质混合体中的组分,经常在用质谱仪分析前使用一维或二维色谱仪进行分馏。通过在一个全细胞酵母裂解液中运用这种方法,已经鉴别出了189种蛋白质,最近又鉴别出了1484种蛋白质,包括细胞中一些基本膜蛋白和低丰度的蛋白质。
与质谱仪相配合的是酵母双杂交系统(yeast two-hybrid system),它已经日益“基因组学化(genomicized)”。在酵母双杂交系统的初步应用中,可以从一种蛋白质出发去发现与之相互作用的许多相关蛋白质,这种方法已经得到了越来越多的使用,得到的蛋白质例如:酵母mRNA剪接中涉及的15种蛋白质、美丽隐杆线虫发育中涉及的29种蛋白质、T7噬菌体中的将近55种蛋白质、牛痘病毒中的266种蛋白质,以及酿酒酵母中的5345种蛋白质。就酵母而言,涉及到至少2000种不同蛋白质的2700多种推定的反应已经被识别,其中大多数是通过双杂交实验得到的。
蛋白质在细胞内的定位现在可以在一种基因组水平上得以解决。应用转座子标记和分析的绝妙技术,得到了11000种酵母株系,其中有2000多种酿酒酵母基因受到影响。然后,再用间接免疫荧光技术来为超过1300种标记蛋白质进行亚细胞定位。同时,生物化学也正在感受全套人类基因组序列信息的影响。已可应用一种生物化学基因组学战略(biochemical genomics strategy)。可通过化验出某种生物化学活性来鉴定与这种活性有关的蛋白质。
由于可以得到的基因组序列数目的急剧增加,人们还开发出了巧妙的算法,可以不依赖氨基酸的相似性,对以前未知的蛋白质认定其功能。
尽管严格地讲,DNA阵列技术不是一种蛋白组学技术,但它也常能够帮助人们认识一定数量的蛋白质的集合的功能。微阵列技术可以鉴别蛋白质的类别——例如,一些膜结合蛋白和分泌蛋白已经通过它们的mRNA的定位得到了识别,而那些与一段DNA序列相结合的蛋白质已经通过它们与一种双链DNA阵列的反应得到了识别。基于微阵列的实验也可以用来检测多态性(DNA中的变异),因此而将蛋白质变异本与某种疾病状态联系起来。
尽管目前基因组学和蛋白组学研究风起云涌,我们应该记住:某种被发现“在剪接小体复合体中”、“与肌动蛋白反应”、“与一种朊蛋白共进化”,或者“在白血病中上调”的蛋白质,其功能并未在生物学家们所熟悉的传统意义上被认识。相反,这类结果常常只是用来将某种蛋白质置于作进一步分析而已。
我们要往哪里走
到目前为止,大多数蛋白组学研究已经以一种编目分类学模式进行,但是在将来我们将看到更多的研究解决细胞学机制的动力学问题。一个细胞的蛋白质组成不是固定不变的,因此,在一个细胞环境改变后进行(该细胞的蛋白质组成的)定量比较是很重要的。蛋白组战略为实现这样的定量分析提供了愈来愈大的可能性。用质谱仪进行定量的研究尚处于早期阶段,其发展潜力巨大。蛋白质的分析将愈来愈以批量化的方式进行,以探索它们各种不同的修饰。用质谱仪对由复杂蛋白质样品降解而得的肽混合物进行的直接分析法已取得很大进步,从而导致在一次实验中就可以识别蛋白质的数量逐步升高。这种方法可以使用人体组织作为蛋白质的来源,并为发现早期的疾病标记物提供可能(通过比较病原细胞及其正常细胞中的蛋白质成分)。
蛋白质表达和提纯技术将继续得到改善。标记蛋白质的提纯池的生物化学基因组学战略,将尤其适合于那些数目众多的已经完成基因组测序的细菌,当然也可以用于多细胞生物体。这些技术和其他可以使用蛋白质阵列的方法将成为一种常规的事情。这些阵列的产生方法包括:标记蛋白质的活体表达、离体翻译,肽合成,或者用抗体或寡核苷酸多聚体进行蛋白质捕获。它们的潜在应用包括:揭示蛋白质之间、蛋白质与小分子(药物)或其他配体之间的相互反应,识别某种修饰酶的底物,例如某种蛋白质激酶,从而查寻该蛋白质的酶活性。
如果要使蛋白质数据库能够帮助科学家们了解数量巨大的实验数据资料的生物学意义,这些数据库将需要变得更加复杂。这种要求包括示踪某个蛋白质家族(例如SH3结构域)的每个被分析成员的所有配基,也包括对每个蛋白质激酶、蛋白质磷酸酶或其他修饰活性的所有已知底物进行编目分类。另外,蛋白质数据将需要用来与表达谱、基因组水平的突变或反义分析,以及多态性检测等的结果进行综合。随着蛋白组学数据的积累,我们将从许多各自不同的零碎信息中测绘出某种蛋白质在细胞中起什么作用之类的生物学意义来。当蛋白组学可以从以前未知的蛋白质直接提出关于它们功能的富有想象力的假说之时,它将变得更加成熟。
我们还需要什么
对于一个如此充满了过时方法的领域,令人吃惊的是在蛋白组学中第一需要的可能是新技术。仅仅有足够的流水线以使得可以自动化进行基因组水平上的蛋白质研究是不够的。目前使用的那些技术只能触及生物学家们每天用来对他们偏爱的数以千计的蛋白质进行的特定分析的表面。我们需要的是一些为蛋白质的功能研究提供线索的实验战略,包括所谓的细胞生物学基因组学(cell biological genomics)、生物物理基因组学(biophysical genomics)、生理基因组学(physiological genomics)等等。另外,一种蛋白质包含有如此多类型的信息,以致其每种性能都需要以一种蛋白组的尺度,最好以定量的方式进行实验研究。正如我们以前所主张的,现在的技术——以及更加重要的是:试剂(基因、质粒、株系、蛋白质等等的集合)和处理这些试剂的实验——必须很快地从专业化的基因组学和蛋白组学研究中心传播到学术界的其他地方。只有当每个实验室都习惯于进行蛋白组学研究的时候,才是蛋白组学完全发挥其效能、建功立业的时候。而且,新方法的发展将与参与此领域的研究者的数量成比例地增加。
遗传学家们需要与化学家们对话,生理学家们需要与物理学家们对话,细胞生物学家们需要与计算机科学家们对话。由于问题的庞杂,回答这些问题需要整个科学的各个分支的综合运用。随着新技术的整合及其广泛扩散以及各个领域的科学计划之间的广泛合作,人类基因组测序计划开始时确定要完成的任务将取得它们的实现,从而使人类基因组计划达到其激动人心的高潮和顶点。
[Science,2001年2月16日]