2024年5月,OpenAI的联合创始人兼前任首席科学家伊尔亚·苏茨克维尔(Ilya Sutskever)宣布离开公司;不久后,他创办了自己的AI实验室“安全超级智能”(Safe Superintelligence),并因此登上新闻头条。
当有研究发现AI能表现出欺骗属性时(详见AI已经开始会违背开发指令,背后偷偷搞事情:撒谎、掩饰、备份数据…),人们可能才对萨姆·奥特曼那场进进出出的政权争夺大戏有更深的理解,苏茨克维尔及离开的研究人员可能只是“先天下之忧而忧”而已。
离开OpenAI后的苏茨克维尔一直远离公众视线,不过在2024年年底温哥华举办的国际AI顶级会议“神经信息处理系统大会”(NeurIPS)上,他罕见地公开露面并发表演说。
这位人工智能领域的关键人物一直引领创新前沿,对AI未来发展有着远见卓识。他的观点和预见可能引发技术与哲学的争辩,同时也蕴含变革的力量——正如NeurIPS会上的他所描绘的AI前景。
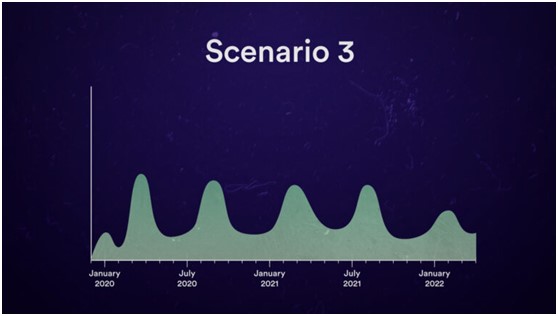
在苏茨克维尔看来,现阶段很流行的预训练(pre-training)日后将退出舞台。
目前正处于AI模型开发的第一阶段,大型语言模型可以从大量无标签数据(unlabeled data,通常是取自互联网和书籍等来源的文本)中学习模式,然后以此应对各种任务,但就像历史上出现过的“石油峰值”,数据的峰值也会到来,可用于AI训练的现存数据集资源已接近枯竭。
数据稀缺可能带来革命性的变化,迫使行业改变现有训练方法,推动AI系统从传统的数据密集型模式转向实时的学习和推理——它们会基于有限的输入得出结论,类似人类的推理和适应——而这标志着AI向更具代理性、能够自主决策的形态转变。
“我们已经达到了数据的峰值,不会有更多的了。”因为就像石油是种有限资源,互联网也只能给AI提供有限的人类生成内容。
上述观点与当前旨在完善AI能力的全球整体趋势契合。
OpenAI和谷歌等大型科技公司正调整战略重点,开发只需较少预训练的模型,减少AI对大规模数据集的依赖。与苏茨克维尔观点的这种一致性凸显了行业的集体转变,旨在接受人工智能不断发展的范式的限制和机遇。

苏茨克维尔将预训练所需的数据集称作人工智能的“化石燃料”
另一方面,苏茨克维尔预测下一代模型将更加自主,“真正具有代理性”。
“代理”已成为人工智能领域的一个流行词。虽然他在演说中并未给“代理”一词下定义,但大家普遍认为,所谓的代理式AI能够自主地执行任务、做出决策以及与软件交互。
未来AI除了具备代理性,还将以更接近“思考”的方式来推理,来一步步解决问题。当前的人工智能主要根据曾经看到过的内容来针对新提示进行模式匹配。
苏茨克维尔认为,系统推理得越多,“就变得越不可预测”。一个“真正会推理的系统”,其不可预测程度大概就是“让顶尖人类棋手猜不透”的程度。“它们会从有限数据中理解事物。它们不会感到困惑。”
随着技术的图景不断演变,随着代理式未来渐显轮廓,不可预测性让人类难捉摸,我们对AI的伦理思虑越发深重。
一个不可预测、能像人类思考一样进行推理的AI,它应拥有某些权利吗?它该如何与人类共存?对技术的总体治理是否应考虑它的特点?正如欧盟《人工智能法案》所探讨的,我们需要在AI领域设立关于伦理的法规,而这种需求也凸显这样一种共识:负责任的AI发展可以维护社会利益。
苏茨克维尔还将AI系统的扩展与演化生物学进行类比。他引用了科学研究中不同物种大脑与身体的质量比例关系,并指出:大多数哺乳动物遵循同一种扩展模式,但人科(人类祖先)的脑体质量比在对数尺度上呈现不同寻常的发展规律。
他认为,恰如生物进化赋予人科大脑以新的扩展模式,人工智能领域也可能出现超越现有预训练方式的另一种扩展模式。

人工智能系统与演化生物学的扩展规律比较
当苏茨克维尔结束演讲后,有一位观众问他:研究人员如何才能为人类创建正确的激励机制,从而打造“像我们人类一样拥有自由”的人工智能?
苏茨克维尔表示自己“没有信心回答这样的问题”,因为这需要“自上而下的政府结构”。“从某种意义上说,如果人们拥有AI,而AI想要的只是与人们共存并拥有自己的权利,那样不会是坏事,可能还挺好的……”
资料来源:
OpenAI cofounder Ilya Sutskever says the way AI is built is about to change
Ilya Sutskever's Vision on AI's Future
END