本文作者、康奈尔大学肿瘤病理学教授马克·罗宾(Mark A.Rubin)呼吁:要推进精准医疗的实施,临床上应该结合肿瘤患者的基因组数据和与临床资料,有针对性地进行诊疗服务。

十个月前,美国新泽西州的一位76岁的售货员因患有尿道晚期癌症而焦躁不安,医生们决定尝试一种非常规的疗法。之前,他们将这位女患者的肿瘤样本分别邮寄到康奈尔大学威尔医学院精准医疗研究所和纽约长老会医院。基因测序显示,她的HER2基因(该基因也称为ERBB2)有比正常人更多的拷贝数。
在多年的常规手术治疗、化疗、放疗均告失败之后,医生们决定对这位女患者采用赫赛丁(Herceptin,曲妥单抗,通常用于乳腺癌的治疗)药物靶向治疗。自从使用了该药物之后,患者逐渐开始摆脱了病魔的困扰。
就这位患者而言,基因组测序明显增加了发现基因突变的概率。基于突变会导致一些特定人群的肿瘤,甚至肿瘤中一些特定细胞的生长。但在现实中,大量的基因组数据却无用武之地,并没有和临床信息结合在一起,比如家族病史。而且,基因组数据一般不宜公开,大多数临床医生因此也无法分享这些数据。
为了达到奥巴马总统倡导的精准医疗在癌症诊疗中的效果,患者就诊时应该能实时获得自己的基因测序数据,同时,这些数据或临床资料可以通过某种特定的搜索途径为医患双方和研究者所利用。尽管集约型数据库大有前途,但仍然需要持续的投资扩大其规模。
复杂的记录
通常,临床医生们习惯于从实验室检查中评估20到50个测量值,比如,血糖水平等数值,这样的数据可以轻易地进入病人的电子病历。而基因组数据的复杂性与常规数据则不能简单类比。
这里大致描述一下基因组数据应用的过程。比如,将癌症基因组(开始于2005年的一项将癌基因突变进行分类的美国国家项目)产生的2.5个PB(1PB相当于1 000TB)数据从一台服务器转移到另一台服务器用时就要超过25天。这是纽约基因组研究中心信息部(一个致力于大规模人类基因组测序的机构)负责人托比·布罗姆(Toby Bloom)讲述的。
通常,人体基因组报告很少以电子形式被利用,也很少与病人的基本信息绑定。例如,国际癌症基因组协会(ICGC)对近1.4万名患者的肿瘤样本所做的全基因组测序,显示有近1 300万个基因发生突变。除了基因突变,包括个人DNA等其他因素都会影响患者对特定治疗的反应。遗憾的是,在ICGC的努力下,只有很小部分的临床数据被利用,例如肿瘤的类型与大小等(参见“缺失的信息”图表)。
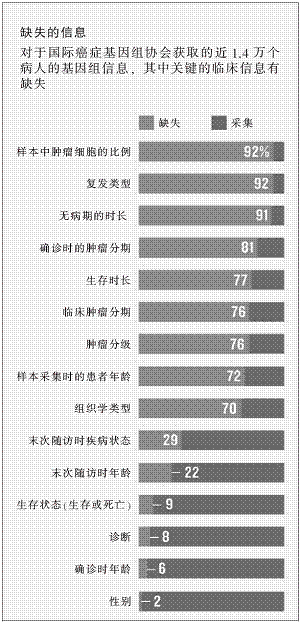
来源:国际癌症基因组协会
自2013年以来,在与意大利特伦托大学综合生物学中心的计算机生物学家开展的项目合作中,即实时绑定基因组与临床数据的可行性研究。迄今为止,我们已经为250个癌症患者创建了一种易于阅读报告的形式。
每份报告都带有一个条形码,在允许病人根据需求识别和重新识别的同时,条形码被设计成可以进入纽约长老会医院或威尔医学院的电子病历系统。采集的资料就类似于病理结果一样,从中可以获得临床信息(包括家族病史、用药史等)、突变信息(一些特异性药物所致),以及一些未知因素造成的基因异常等。
尽管没有足够的证据支持尝试未批准药物的安全性等原因,但我们发现有超过90%的患者所携带的突变对一种已知药物会产生反应,只有不到10%的患者适合临床试验。
为了广泛获益,这些数据需要在机构之间共享。例如,现在正致力于测试来那替尼(neratinib)药物有效性和安全性,而患者体内的肿瘤受到了HER2或者EGFR基因突变的影响。除了肺癌(EGFR基因突变在肺癌很常见),这些突变的频率在1%-6%之间,所以要达到二期临床所需的病例数,则意味着要从多个医疗中心招募志愿者。在机构之间分享数据可以使招募工作变得高效――这或许可以改变目前慢得几乎让人沮丧的招募过程。
数字化资料
目前,相关机构在尝试制定公共数字化医疗数据资料的新标准,其中,非盈利性质的纽约临床数据研究网(NYC-CDRN)就是其中一个例子。在位于华盛顿特区的以病人为中心的实效研究所的资助下,NYC-CDRN汇集了22个公共机构,由康奈尔大学威尔医学院和纽约长老会医院记录和管理这些医疗数据资料。
互不兼容的电子系统是传递病人记录的一大障碍。
在16个月的时间里,NYC-CDRN已经拥有了超过600万条记录和成千上万的源数据,范围涵盖从血钙水平的测量到磁共振成像扫描结果。他们最终目标是覆盖数据库中的所有基因组数据,便于纵向追踪病人的情况。特别在一些拥有私人医疗系统的国家中,建有共享的、标准的、可搜索病人资料的中心数据库,是最可行的方法。
对于精准医疗用于癌症的诊疗而言,现在看来是显而易见的。举个例子,正如大多数靶向治疗中存在的耐药性问题――显然是作为最有针对性的治疗措施。但针对BRAF基因突变(在60%的黑色素瘤中可见)的药物,或针对IDH1和IDH2基因突变(在80%的脑部肿瘤中可见)的药物,不是被批准用于临床,就是处于临床试验中。在法国多个机构中展开的有史以来最雄心勃勃的精准医疗试验,在708名参与者中,其中有141名患者被匹配了对应的药物靶向治疗。
资金的问题
然而,精准医疗若要获得成功,其关键还在于拥有足够多的患者信息,而数据库里患者的具体信息越多,则难以保证这些患者的信息不被外泄。包括人们对个人的健康资料拥有什么权利,以及这些数据是否国际共享?同样不明确的是,究竟由谁管理这样的数据库,而谁又应该为此承担费用。
NYC-CDRN迄今已投入了700万美元。随着更多信息的融入,成本将不断会提升。相应的,治疗本身的费用也将会增加――目前癌症靶向治疗的年费用或超过10万美元,而多数患者只能延长几个月的生命。
如果能延长患者3个月生命的话,那么那些在百分之十人群中被发现的基因突变,其靶向治疗药物是否应该被研发和使用呢?还是说,只有药物能够延长患者至少一年以上的生命时才应该被支持研发呢?
更复杂的是,许多药物的潜在好处是在它们被批准使用后才显现出来。如赫赛丁,最初由美国食品和药物管理局(FDA)批准为针对转移性乳腺癌的治疗药物,可以延长患者几个月的生命。后来,该药被发现还可以提高早期乳腺癌患者的长期生存率。
如今,一些国家已经给出了精准治疗的量化指南。英国国家卫生与临床优化研究所(NICE)根据乳腺癌治疗中不同类型的基因组测试数据,在2013年9月推荐了一种名为oncotype DX的癌症基因检测方法,以作为临床决策的制定。同时也决定其他三种目前可用的基因组测试结果仅限于研究,这是因为目前尚无可靠的证据支持它们在临床护理中的有效性。
尽管有许多理由值得我们期待。然而,将基因组潜在的价值转化为癌症的靶向性治疗,仍然需要我们在技术上创新、打破观念的藩篱,乃至持续的经费投入。
资料来源 Nature
责任编辑 则 鸣