自从有了人类基因组计划(HGP)以来,现在已有数以千计的“组”计划。《自然》杂志对其中五个引人注目的新组学进行了评述。或许,它们代表了科学的一种新境界。

目前生物学中最时髦的科学,毫无疑问当数组学了。去年,《纽约时报》和《华尔街时报》对以“组”字结尾的、不断扩增的相关科学名词进行了检索,发现已经多达数千个了。一位科学家开发的一种简易的组学生成器,可以随机地在一张清单的生物学术语后面加上“组学”这个后缀,可以生成浅显易懂的主题词用于科学论文的写作和发表(例如,“对抑菌剂组进行测序”提示对进化和环境的关系问题进行新的研究和发现)。加州大学戴维斯分校的一位微生物学家乔纳森·艾森(Jonathan Eisen)在他的博客中定期公布不需要的新组学科学单词集(近期的上榜单词是:研究与生物钟相关基因的“生物钟组学”)。
迎接组学的挑战
1920年,当植物学家汉斯·温克勒(Hans Winkler)最初提出“基因组”这个单词时,并没有想到这个单词会有今天的辉煌――意指对一套染色体的研究。当时还有其他以“组”字结尾的单词,但都不同于现在的含义,例如“生物组”(原指生命体的总称)和“根组”(原指根系统),它们中许多含有希腊文后缀“组”,大致含义为“有……的本质”。但是,只有如同HGP这样的大科学项目才真正使“基因组”如此令人着迷,趋之若鹜。哈佛医学院的语言学家兼医学信息学家亚历克萨·麦克格雷(Alexa McCray)说:“凭借着这个后缀的力量,你就可以说,你正在融入一个崭新的令人激动的科学中去。”
研究人员还意识到一个令人鼓舞的音节的市场化潜力,艾森称:“人们正在意识到它是一个独立的领域,值得人去为它设立独立的机构。”尽管一些“组”使人们产生疑惑,比如“博物馆组学”(对馆藏样品的测序计划)和“纤毛组学”(对一些细胞上的头发样蠕动物的研究),科学家们仍然坚持认为至少这些“组”会为好的目标服务。西雅图儿童医院首席数据官、《组学》杂志主编尤金·柯尔克(Eugene Kolker)说:“大多数“组”可能不会带来什么科学价值,但其中的有些“组”会,这就需要一种平衡机制。如果我们只会哗众取宠地玩弄不同的新词汇术语,那不会是件好事情。”
理想地说,如同“组”这样崭新的领域有助于激励大科学思维、定义研究问题和指明分析方法。耶鲁大学的计算生物学家马克·格斯坦(Mark Gerstein)说:“我认为‘组’是一个非常重要的单词后缀,它吹响了基因组学的号角,或是激动人心的进军曲。”在此,《自然》杂志对五个引人注目的新组学进行了评述,或许它们代表了科学的一种新境界。
偶然组(Incidentalome)
在高通量测序使个人基因组成为现实前几年,在波士顿儿童医院从事医学信息学研究的艾萨克·柯恩(Isaac Kohane)提出了术语“偶然组”作为一种警示。他在2006年的一篇论文中预测,数量急剧增加的遗传学信息将有朝一日对医学形成挑战。
该术语来源于“偶然瘤”,这是一个放射学家的专门术语,意指医生们对其他疾病放射扫描时发现的无症状肿瘤。偶然组描述的是人类基因组分析中的同义词:人们没有研究的遗传学信息。例如,对一位听力丧失的儿童的遗传学原因的研究,可能转化成为将来心脏病的线索或癌症风险升高的线索。但是,有谁会说出它们是什么?什么时候出现呢?在越来越多的人类基因组得到了测序的时代,美国国立人类基因组研究所(NHGRI)认为,向个人披露关于他们自己的DNA信息,将是“基因组学研究人员面临的最棘手伦理学问题之一”。
去年的一项研究揭示了这一问题面临的两难。它综述了16位遗传学家对大规模测序可能发现的涉及99种常见的遗传病的突变研究,不论医生们是否寻找这些突变。对于包括与特定癌症和心脏功能紊乱关联的已知序列变异的大约21种疾病或基因来说,16位专家建议对成年患者进行研究。但是,其中只有10种对于杭廷顿氏病来说是一样的(一种不治之症)。相对来说,更多含混不清的突变几乎没有一致的,也没有什么可以告诉父母在儿童序列中什么时候出现变异本。
偶然组中最大的问题是,没有人能够知道什么是健康最重要的序列变异本,而且,这样的序列在每个人类基因组中有超过300万之多。纽约哥伦比亚大学的临床遗传学家钟温迪(Wendy Chung,音译)正在开发一些方法来帮助研究参与者和患者选择哪些遗传学结果是他们想要了解的,包括对这些信息的行为和心理社会学影响进行了测量。她说:“如果你问人们什么是他们想要了解的DNA序列,每个人最初要么说都想了解,要么说没有什么要了解的。如果他们有思想准备的话,回答会是不同的。”
随着临床测序变得普及,偶然组的定义和规模正在变得模糊不清。西雅图儿童医院的生物伦理学家霍里·塔伯尔(Holly Tabor)说,遗传学家们应该预期到这些难以处理的结果,“如果说基因组研究中存在偶然的结果,这多少有些误导。你知道它们最终会被发现的。”
表型组(Phenome)
人类基因组现在很容易得到,而其迷人之处在于表型组:对一个人每种体格和行为特征的彻底、精确描述。研究人员最想知道的是与疾病相关的人类表型组部分:面部畸形、肢体残疾、人们是否或如何被诊断为抑郁症。而且,他们希望那些描述的形式是计算机可读的,更进一步,能够见到这些表型性状是如何可能与基因组关联的。“我不知道还有什么单词或词组可以将此表述得更加好,”柏林慈善大学医院的计算生物学家彼得·罗宾逊(Peter Robinson)说。
表型组计划已经在小鼠、大鼠、酵母、斑马鱼和拟南芥植物中进行。在系统的努力中,科学家们一个一个地敲除基因、然后仔细地对生物体进行一系列的测量和物理检测,以发现基因是如何构成物理结构、新陈代谢和行为的。类似的综合数据不可能在人类基因中获得,尽管一些临床研究人员希望通过收集患者的数据来获取一些资源。
即便是孟德尔病,即由一种突变基因导致的疾病来说,将疾病与基因匹配起来也是具有挑战性的。在超过6 000种这样罕见、可遗传的疾病中,只有不到50%找到了遗传学原因。最困难的是难以发现足够多的这些疾病的患者,其发病率不到百万分之一。西雅图华盛顿大学的一位遗传学家迈克尔·巴姆沙德(Michael Bamshad说:“如果我们能够得到足够的表型良好的病例的话,我们大致可以解决其中大多数原因未知的孟德尔疾病。”
但是,如何了解其中的因果原因呢?许多学术或疾病协会已经拥有了各自的信息学工具和词汇用来描述各种疾病详细的表型细节。挑战在于将这些资源整合后一起以发挥作用。澳大利亚墨尔本大学的遗传学家理查德·科顿(Richard Cotton)解释说,如果一位临床医生输入“胃痛”和“胃肠炎”两个单词,有相似症状的患者可能并不会集中在一起。
去年11月科顿参加了在旧金山市举办“为人类表型组计划做准备”的学术会议,会议主题是使表型数据交换更为容易。一个致力于研究罕见疾病的“Orphanet”联盟,力求对1 000至2 000个标准术语达成一致,例如“短小身材”,可以分类成“身高减小”、“身高低于第三百分数”或“小身材”。约翰·霍普金斯大学医学院的临床遗传学家埃达·哈摩什(Ada Hamosh)说:“只要同意有关术语,不论你拥有什么形式,我们都可以共享彼此的思想。”
其他一些研究人员正在试图将电子医学档案上的信息用计算机进行梳理分析,并对常见表型进行自动分类。柯恩说:“数据如同生铁一样是丑陋而离散的,而神奇的科学则正在炼铁成金。”
相互作用组(Interactome)
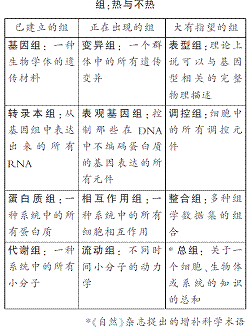
生物学中心法则是经典的,这就是从DNA转录成RNA,然后翻译成蛋白质。它们相应地构成三种基本的组(基因组、转录本组和蛋白质组),而生命就是由这些组共同运作而形成的。神经元的相生相灭和细胞的相生相灭都是由这些分子的相互作用构成的。相互作用组就是用来描述所有这些分子的相互作用的。就其复杂性而言,它是“组”之王,即使只考虑两万种左右蛋白质的一对一互相作用,也会产生两亿种可能性。
这种海量数据对于马克·维达尔(Marc Vidal)这样的研究人员来说却不是那么可怕的。据这位50岁的波士顿市达纳——法伯尔癌症研究所的系统生物学家称,在他退休之前希望能够见到基因组编码的所有相互作用的第一幅草图。事实上,他更喜欢其中的一个子集,即成对出现的所有蛋白质的目录。“那是我们在过去20年中所做的一切,现在快要完成了。”
在这些将要完成的工作中,维达尔实验室和其他实验室已经观察了10%——15%的人类蛋白质——蛋白质的相互作用,即基于一对蛋白质结合时产生的一个信号导致遗传工程化细胞研究之上的。其他研究人员则从捣碎的细胞中寻找蛋白质、示踪彼此的反应情况,并根据蛋白质外形和相关分子的行为进行计算预测。
在第一次大规模相互作用组研究之后的十多年,研究人员开始处理哪些相互作用是真实的、哪些是人为的。要做出这样的甄别需同时使用多种技术,目前生物学家们正在对相互作用组进行分析。
康奈尔大学的系统生物学家于海元(Haiyuan Yu,音译),检测了大约1 800万潜在的蛋白质对,最终鉴定出了7 401种人类蛋白质之间的20 614种相互作用。对于这些相互作用来说,于海元团队还了解到这些蛋白质(部分)产生接触的区域,初步证明了致病突变更可能在这些触点上发生,而不是蛋白质的其他部位。比如,血液病威——奥综合征是由一种称为WASP的蛋白质中的突变引起的,但只能由定位于一个与第二种称为VASP的蛋白质相互作用的区域中的突变引发。于海元说,那些对于基因来说可能没有意义的模式,但在考虑相互作用的情况下会变得明朗。
维达尔认为,可以将相互作用组中日益复杂的信息进行分层。第一层是扁平的基础网络:蛋白质目录和它们的结合配体,理论上可以用不同的细胞类型进行注释;第二层将是叙述性数据,比如相互作用持续多久、其必要条件和接触的蛋白质部位。
维达尔还展望了这样的未来:当临床医生诊断一个患者时,不仅要考虑他的基因组,还要考虑所有他的序列变异本对相互作用组的影响结果,但他没有提及相互作用组对表型组的影响。圣地亚哥加州大学的系统生物学家特雷·艾德克(Trey Ideker)说,基因组一般来说是静态的,“序列不能被药物、组织或其他条件所扰乱,而相互作用组却可以。”
毒物组(Toxome)
托马斯·哈顿(Thomas Hartung)希望了解小分子伤害人们的所有方式和路径。为此,他组建了人类毒物组计划,从美国国立卫生研究院(NIH)获得了600万美元的五年期资助,还从美国环境保护局(EPA)和美国食品药品监管局(FDA)获得了附加资助。哈顿认为,后缀“组”适应了他研究目标的规模:对引起毒性的整套细胞过程的描述。“毒物组非常类似于人类基因组,因为它建立了一种参考文献点。”哈顿是位于巴尔的摩市的约翰·霍普金斯布鲁姆伯格公共卫生学院的一位毒理学家。
动物研究中的毒性检测要为进入人体试验的每个化合物耗费数百万美元,而且动物实验有时还不能预测人体中的毒性。在人体试验中发现的药物中每六个会有超过一个因安全问题被撤出。哈顿说,毒物组有助于引入一系列直接的基于细胞的实验,可能替代动物检测。了解一个化合物可能引发什么样的毒性相关过程还有助于科学家将富有前途的药物或者产业化分子改造成较少毒性的变体。
要着手解决这个问题,哈顿希望将细胞暴露于毒性化合物中,然后监测它们的代谢组(该细胞中所有小分子的集合)和转录本组情况。他希望通过这种方法,将以下人体细胞通路的细节整合在一起:破坏激素信号、毒害肝细胞、损坏心脏节律和其他可能破坏人体健康的情况。哈顿相信,这些通路的总数有可能是200,这是一个检测毒性中可以控制的数量。
该项目目前仍处于早期阶段:确保相同实验在不同实验室产生相同的结果。但是,那些通路将最终用于基于细胞的实验以服务于毒性检测。FDA的大卫·雅可布逊-克拉姆(David Jacobson-Kram)在评价毒性预测的方式时说:“我们应该知道,如果我们刺激那些通路之一,就会有一些坏事情发生。我们应该知道会有什么样的不良事件发生。”他同时警告说,一个在培养物中似乎对细胞无害的分子在人体内表现可能会不一样,比如,肝脏可能会将其转换成为一种毒素。无论如何,他说,毒物组计划可能为人们节省时间、金钱和实验用动物。“我个人认为这种方法是绝对有前途的。”
整合组(Integrome)
柯尔克认为,要揭开生物学最大的奥秘,关键并不在于发明一种新的组,而是在于将那些已经存在了的组整合在一起。“单独一种方法是解决不了问题的。”于是,人们就想到了整合组:将所有组的信息融合在一起进行综合分析,并比对其他数据以寻找更好的方法。柯尔克说:“那是真正的问题关键,它将会变得越来越重要。”
以“谷歌”地图为例:一些分离的加油站、旅馆和街道的目录清单,远远不如一幅显示着一个加油站位于一个旅馆所在街道的地图来得有用。但是,许多传统的组学研究仍然停留在制作目录上,也就是制作基因、蛋白质或RNA转录本。它们可能忽视了网络的作用,有许多也被发现确实如此,例如,不同的基因的改变事实上汇聚成了相同的通路。
艾德克已经向人们证明了,自动化分析不同的组学数据是有可能的。他编写了一套软件,对四个这些模式数据的集合进行分析,然后使用这些结果独立地运行出了相关基因所行使的功能。这套软件不仅帮助描述了现有基因组资源的各个部分(例如,鉴定有助于处理废弃蛋白质的细胞机器部件),它还开始填补了这样的空白:发现那些功能未知的基因的相似组织模式。“我们抽取了转录本组和相互作用组数据,推断了一个细胞部件中的全部不同级别的结构,”艾德克说,“我为这项技术而激动,赛过了长久以来我从事的任何事情。”这样的算法并不能替代人类的数据管理员工作,但是,它们可以发现人类或者那些从发表论文中抽取论文关系的文本挖掘软件可能遗漏的模式,他说:“细胞并不能讲英语;它们讲的是数据。”
去年,加州斯坦福大学的一位遗传学家迈克尔·施耐德(Michael Snyder)将他的基因组、转录本组、蛋白质组和代谢组数据整合在一起,发表了他的个人整合组(尽管他称其为一项“综合性个人组学表达谱”,其他人则称之为自恋组)。基因组学表达谱提示施耐德有一种糖尿病的风险变异本:在研究期间他被诊断出了这种疾病,并有两种病毒感染,这反映在一些与炎症相关联的基因的活性增加;各种组数据还提示一些以前与糖尿病或感染不相关的通路的改变。施耐德说:“如果你只分析了转录本组或蛋白质组数据,你就只了解了故事的一部分。”
格斯坦认为对数据集进行整合是前进的必由之路。他说:“未来将属于将这些东西放在一个网络里以理解个人基因组。”但是,他对“整合组”却不以为然。他解释说:“什么是一个整合组?所有整合的总体?我不这么认为。整合是一个动词,其他组的大多数都是名词的集合呀。”
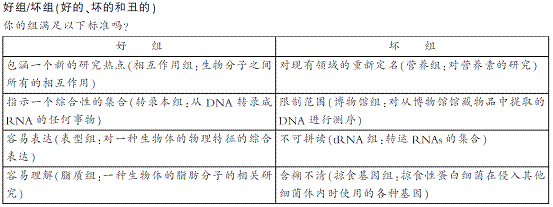
“组”词的扩增反映了科学的发展步伐。麦克格雷对构成有用的“组”词提出了一些指导规则:有意义、听起来令人愉快并且易于为受过教育的读者所理解。但是,要想让许多科学家都关心这些规则,是不太可能的。语言一般的变化是很慢的,但是后缀“组”和“组学”的快速传播“在过去十年中达到了正常情况下五十年的规模,它反映出大量的人力财力物力投入到了这个领域中。”
资料来源 Nature
责任编辑 则 鸣