如果我声称美国人最近变得更加以自我为中心,你可能会把我视为一个爱发牢骚爱怀旧的倔老头,但是如果我说通过分析1 500亿个文本词汇,我能支持这个断言,你又会怎么看我呢?请看卡耐基梅隆大学计算机科学博士研究生杰西·杜尼艾茨(Jesse Dunietz)的分析。

几十年前,这种规模的证据只是一个白日梦。而现在,1500亿个数据点实际上已经过时了。一股对“大数据”分析的热潮席卷了生物学、语言学、金融学以及它们之间的每个领域。
尽管对于如何定义“大数据”尚未达成完全的共识,不过一般的观点认为,数据集庞大,以致能揭示传统数据查询见不到的模式,这就是大数据。数据通常由数百万现实世界中的用户行为产生,比如Twitter文章或信用卡购买记录,需要利用成千上万台计算机收集、储存和分析这些大数据。不过,对很多公司和研究者而言,对大数据的投入是值得的,因为其模式能破译关于任何事物的信息――从遗传病到明天的股票价格。
但是有一个问题:人们想当然地以为拥有如此海量的数据作为支撑、依赖于大数据的研究不会出错。但是,数据量的巨大可能会为研究结果灌注一种虚假的确定性。很多基于大数据的研究很可能是虚假的――而其中的原因应该让我们对任何盲目相信大数据的研究有所质疑。
在语言和文化研究方面,大数据于2011年大大露脸,当时谷歌推出全球书籍词频统计工具Ngrams。在《科学》杂志上大张旗鼓地发布后,Google Ngrams允许用户在谷歌图书数据库中检索短语(谷歌扫描的图书数量大约占到现代印刷术发明以来人类已出版图书总量的4%),然后看看这些短语出现的频率是如何随着时间变化的。这篇论文的作者们预示了“文化组学”(culturomics)的问世――这是一种基于大量数据的文化研究,从那以后,Google Ngrams很大程度上成为了娱乐的无尽源泉,同时也成为语言学家、心理学家和社会学家的金矿。他们遍览数百万册书籍,最终得出一个研究结论,比如说,美国人确实变得越来越个人主义,“我们年复一年越来越快地忘记我们的过去,道德理想正从我们的文化自觉中消失。”
问题开始于Ngrams语料库建立的方式。去年10月发表的一项研究中,佛蒙特大学的三位研究者指出,总体而言,谷歌书籍数据库(Google Books)包括了每本书的一个副本。这对它创建的初衷而言非常有意义,那就是把这些书的内容暴露于谷歌强大的搜索技术。但是,从社会学研究的角度而言,这使得语料库被危险地歪曲了。
更逃避不了的事实是,Ngrams并不是正在出版书籍的一致而均衡的切片。同样是佛蒙特大学的上述研究表明,在书籍结构的变化中,尤为突出的是从20世纪60年代开始科学文章的显著增长。所有这些因素都让我们很难相信,谷歌Ngrams准确反映出词汇的文化流行度随着时间的变化。
即便你不考虑数据来源,在解释上仍然存在很多棘手的问题。的确,像“character”(性格)和“dignity”(尊严)这样的词汇出现的频率随着时间在降低,但是这就意味着人们对道德的关注减少了吗?不会这么快减少的,伊利诺伊大学厄巴纳-香槟分校的英语教授泰德·安德伍德(Ted Underwood)提醒研究者下结论要慎重。20世纪末的道德概念很可能与我们现在的道德概念有很大的不同,他指出,“尊严”这个词可能出于并非道德方面的原因而流行。所以,我们通过把现有的联系映射到过去所得出的任何结论都是可疑的。
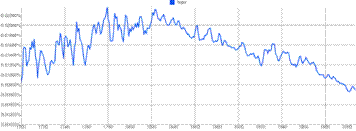
我们正在失去希望:上图是“希望”(hope)这个词的Ngrams词频统计图,这是xkcd网络漫画的创作者兰德尔·门罗(Randall Munroe)发现的很多有趣的情节之一。如果Ngrams真的反映了我们的文化,那么我们将走向一个黑暗的地方
当然,所有这些问题对于统计学家和语言学家而言,都算不上新鲜事。他们天天跟数据和解释打交道,就像每天吃的面包和黄油,不过,谷歌Ngrams的不同之处在于,纯粹的数据会产生一种诱惑,让我们变得盲目,可能会让我们误入歧途。
这种数据的诱惑并不是Ngrams研究所独有的,类似的错误也会损害所有类型的大数据研究项目。比如,我们看看谷歌流感趋势(GFT)的案例。2008年发布的GFT研究在数以百万计的谷歌搜索查询中,统计了诸如“发烧”和“咳嗽”这样的词汇出现的频度,用它们来映射到现在有多少人得了流感。如果采信GFT研究的估计,可能在疾病控制中心(CDC)从医生的报告中计算出真实数据之前两周,公共卫生官员们就会采取行动。
最初,GFT研究结果声称具有97%的准确度,但是一项对美国东北大学文献的研究表明,GFT研究的准确度不过是侥幸。首先,GFT研究完全忽视了2009年春季和夏季爆发的“猪流感”。(原来GFT研究大部分预测的是冬季流感。)其次,该研究体系开始高估了流感案例。实际上,它夸大了2013年流感高峰期的数据,比真实数据夸大了惊人的140%。最后,谷歌只好整体解散GFT研究项目。
那么,到底是哪里出错了呢?对于Ngrams,人们并没有认真考虑其数据来源和解释。数据来源――谷歌搜索,并不是一个静态的野兽。当谷歌开始自动完成查询,用户就开始接受建议的关键词,而扭曲了GFT研究看到的搜索。在解释方面,GFT研究的工程师们最初让GFT采用了表面价值的数据,几乎任何搜索词都被视为一个潜在的流感指示词。采用数以百万计的搜索词,实际上保证了GFT过度解释了具有季节性的词汇,比如“雪”,将其视为流感证据。
但是当人们不把大数据视为万能药时,大数据就可能起到变革作用。有几个研究团队,比如哥伦比亚大学杰弗里·沙曼(Jeffrey Shaman)研究团队,通过利用疾病控制中心的研究结果弥补GFT研究的偏差,得到了比两者都更为准确的流感预测。据CDC说,“沙曼的研究团队对该季节中已经发生的实际的流感疫情测试了他们的模型。”通过把刚刚发生的流感疫情考虑在内,沙曼及其研究团队精密调校了他们的数学模型,以更好地预测未来的流感疫情。研究团队们所需做的就是严格评估他们对数据的假设。
为了避免我看起来像是谷歌的冤家对头,我会赶紧补充说,谷歌远不是唯一的罪魁祸首。我的妻子是一个经济学家,过去曾为一家公司工作,那家公司搜刮整个互联网上的招聘信息,然后汇总成统计数据报告给国家劳动机构。这家公司的经理们鼓吹说他们分析了美国80%的工作,但是再一次,数据的数量让他们变得盲目而误入歧途。例如,当地的沃尔玛超市可能会发布一个与销售相关的职位招聘信息,而实际上它可能想要招聘10个人,或是在招到人以后,让招聘信息依然挂在网上数周不拿下来。
所以,与其屈服于“大数据的狂妄自大”,剩下的我们还不如保持质疑态度,即便有人拿出数十亿的词频分析作为结论支撑。
资料来源 Nautilus
责任编辑 彦 隐